Midterm Project: What Language Does Natural Language Processing Consider Natural?
Problem:
Natural language processing is generally considered to have started with Alan Turing’s work in the 1950s, although the implementation of artificial intelligence into the field in the last decade has given its developers a social responsibility in preventing their technology from perpetuating demographic biases. This includes sexual and racial bias, as well as language bias. While the technology is researched worldwide, the diversity in the United States makes it especially important for American developers to be vigilant with these issues. English may be spoken by 1.75 million globally (Harvard Business Review), but vernacular and skill level brings up the question, what can be considered natural language?
Affected Populations, SSIs:
educated, industrialized, rich, and democratic re-
search participants (so-called WEIRD, Henrich et
al. (2010)), the tacit assumption that human nature
is so universal that findings on this group would
translate to other demographics has led to a heav-
ily biased corpus of psychological data.” (Hovy and Spruit, 593)
The above quote from The Social Impact of Natural Language Processing brings up what I believe to be the umbrella for NLP issues: normativity. The ironically dubbed concept of the WEIRD demographic is the exact narrowmindedness that will limit the power of NLP and systemize oppression. By limiting studies to this group of people, they are given the authority to decide on how sentiment analysis will discriminate against people of color, women, and non-native speakers of any given processed language. Researching one demographic of people will make that normalized group the sole audience of the technology, and it appears as though this demographic is currently occupied by WEIRD people.
Relevance:
APIs that utilize NLP have the potential to entirely reshape how we feed information to computers. If it is made accessible to all, regardless of first language or vernacular, it would greatly improve the fluidity of communication between computers and humans. NLP is also the basis of translation software, including Google translate and Bing translator, and realistically could bring us to an era without language barriers. Virtual assistance software would also be overhauled and differentiated into specialized purposes. Currently, NLP and AI power such applications as otter.ai, which transcribes conversations in real time, and Navigator, an office assistant that helps plan, prepare, and execute on meetings. Not only would these applications grow with the field, acquiring newer and more seamless features, but similar technologies could arise in nearly every aspect of your life.
These processes improve by inputting more and more data - the more accessible this technology is made, the more effective it will be and the more marketable it will become.
Technology Background:
Natural language processing is often considered a data science and since the last decade has been powered by artificial intelligence. It deals with computer-human interactions with language data. The majority of today’s NLP methods attempt to use machine learning to derive meaning from speech. The computer-human interaction can go as follows: human speaks, machine records the audio, machine converts audio to text, the data is processed, the data is converted to audio, the audio is played back to the human.
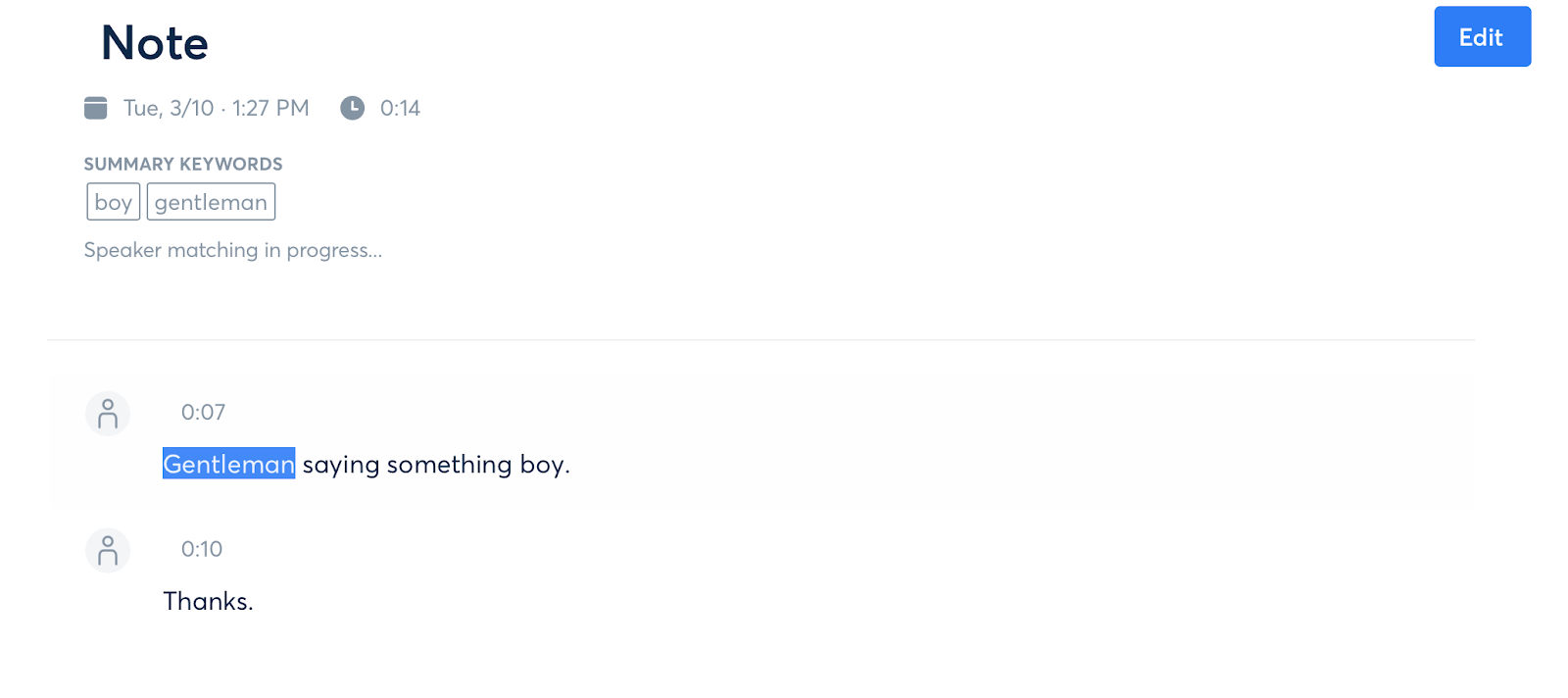
The interface of otter.ai
The two techniques NLP uses are syntactical analysis and semantical analysis. Syntactical analysis involves the machine using the arrangement of words to understand grammar. Some of the syntax analysis techniques include lemmatization, which ignores inflected forms to focus on the base form, segmentation, which divides pieces of texts into smaller information bits (be it words or morphemes), and parsing, which puts the text under grammatical analysis. Semantical analysis is more difficult for the machine, as it grapples with the meaning conveyed by speech. Some of these rules can be too abstract and high level for our current AI to fully understand, one of the most common examples being the use of sarcasm. While it is a part of NLP that has not been fully resolved, there are still tried methods that are proficient in their use. These include NER (named entity recognition), which searches for items that can be grouped or named, word sense disambiguation, which uses context to tag a word with a meaning, and natural language generation, which references databases to figure out semantic intentions.
Diversity Considerations:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer nec odio. Praesent libero. Sed cursus ante dapibus diam. Sed nisi. Nulla quis sem at nibh elementum imperdiet. Duis sagittis ipsum. Praesent mauris. Fusce nec tellus sed augue semper porta. Mauris massa. Vestibulum lacinia arcu eget nulla. Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos himenaeos. Curabitur sodales ligula in libero. Sed dignissim lacinia nunc.
Curabitur tortor. Pellentesque nibh. Aenean quam. In scelerisque sem at dolor. Maecenas mattis. Sed convallis tristique sem. Proin ut ligula vel nunc egestas porttitor. Morbi lectus risus, iaculis vel, suscipit quis, luctus non, massa. Fusce ac turpis quis ligula lacinia aliquet. Mauris ipsum. Nulla metus metus, ullamcorper vel, tincidunt sed, euismod in, nibh. Quisque volutpat condimentum velit. Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos himenaeos. Nam nec ante.
Sed lacinia, urna non tincidunt mattis, tortor neque adipiscing diam, a cursus ipsum ante quis turpis. Nulla facilisi. Ut fringilla. Suspendisse potenti. Nunc feugiat mi a tellus consequat imperdiet. Vestibulum sapien. Proin quam. Etiam ultrices. Suspendisse in justo eu magna luctus suscipit. Sed lectus. Integer euismod lacus luctus magna. Quisque cursus, metus vitae pharetra auctor, sem massa mattis sem, at interdum magna augue eget diam. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Morbi lacinia molestie dui. Praesent blandit dolor.
Curabitur tortor. Pellentesque nibh. Aenean quam. In scelerisque sem at dolor. Maecenas mattis. Sed convallis tristique sem. Proin ut ligula vel nunc egestas porttitor. Morbi lectus risus, iaculis vel, suscipit quis, luctus non, massa. Fusce ac turpis quis ligula lacinia aliquet. Mauris ipsum. Nulla metus metus, ullamcorper vel, tincidunt sed, euismod in, nibh. Quisque volutpat condimentum velit. Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos himenaeos. Nam nec ante.
Sed lacinia, urna non tincidunt mattis, tortor neque adipiscing diam, a cursus ipsum ante quis turpis. Nulla facilisi. Ut fringilla. Suspendisse potenti. Nunc feugiat mi a tellus consequat imperdiet. Vestibulum sapien. Proin quam. Etiam ultrices. Suspendisse in justo eu magna luctus suscipit. Sed lectus. Integer euismod lacus luctus magna. Quisque cursus, metus vitae pharetra auctor, sem massa mattis sem, at interdum magna augue eget diam. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Morbi lacinia molestie dui. Praesent blandit dolor.
Current Solutions:
***As mentioned, the lack of direct human subject research has left out IRBs from the NLP discussion. Resultantly, tech companies and their NLP teams are left largely unchecked, with their main concern being exposure and public image. The three tech titans I looked into took vastly different approaches concerning diversity and inclusion. Microsoft, the longest standing of the three, has backed NLP research in universities in China, Japan, Korea, Singapore, Taiwan and Hong Kong since 1999. Their NLP team is composed entirely of people of Asian descent, which, while not representing the most diversity, is still a step away from typical white dominant research. Microsoft does not appear to address gender and race bias in the NLP research. Alternatively, Facebook boasts their NLP software extensively and makes sure to mention their efforts to include diagnostic tools in their programs that measure program biases. Unlike Microsoft, Facebook mainly addresses the qualifications of their product, and not nearly as much on how they intend to ensure the product’s inclusivity. In stark contrast, Amazon has been criticized for algorithmic discrimination over several of their project, not limited to Amazon Comprehend, their NLP software. Their facial detection bot, Rekognition, came under fire back in 2018. While Rekognition is not in the field of NLP, its criticism ring true for all algorithmic oppression: “It doesn’t make communities safer. It just powers even greater discriminatory surveillance and policing” (Brandom 1).
My Solution:
My Solution:
An issue that orbits diversity independent of technology is the well-meaning but ultimately damaging nature of color/diversity blindness. This controversy is commonly considered to be resolved, but in essence it was criticism of ignoring demographic differences in order to equalize all demographics. There are several reasons this thinking is problematic, paramount of which is that it essentially states that almost anything outside of the aforementioned WEIRD characteristics is not normal and should be swept under the rug. If I were to be approached and told my Asian descent would be ignored, I would perceive that as white-centric and reductionist to my heritage.
With that, I believe it is important that technological solutions to algorithmic oppression do not involve neutralizing the bias, but measuring it instead. In many cases, demographic information of a user is relevant, externally useful, and sometimes necessary. Simplistically, I believe the best possible solution would be to run the software initially blind (lacking demographic information), then rerun the software fully (demographic information provided). Hovy and Spruit bring up the problems of overgeneralization in NLP and how returning a false positive on a demographic can be light and humorous or serious and offensive. It is for this reason that, as we as a society grew out of color and diversity blindness, NLP should be made aware of its own biases rather than being blind to the information to begin with. While humans can handle this type of complex thought naturally, we would need to and should teach NLP programs to compare a blind run to a full run to directly and quantitatively address its bias.

This a method of calculating bias
Interview Recap:

Jared Taylor, one of my interview subjects
While I was unable to arrange an interview with someone specifically working in NLP, I contacted a few of my peers who I knew considered language a salient social identity. The first person I interviewed was Jared Taylor, who criticized voice assistants for forcing him to “speak white.” Anushka Ladha, another person I interviewed, expressed complaints that her accent barred her from many of these applications as well. When I asked if she had used the transcription software otter.ai, she told me she doubted it would be effective. To them, I brought up my proposed solution. Taylor was quick to get behind the idea, saying, “These companies don’t really get the problem. It’s not that the technology isn’t for people of color, it’s just not for people of color who don’t act white.” Ladha thought that the specifics of the process would need to be figured out using the actual code behind NLP, but conceptually the idea of calculating bias using comparison to baseline unbiased data.
Conclusion:
Ladha was certainly right in that the solution needs to be addressed technologically using code from an actual NLP API. If I were to continue developing this solution, first I would have to attain the code behind a software. Google’s BERT is an open source AI that would be a good place to start. From then, I would work on my proposed solution of biased versus unbiased runs to measure that bias. Without that data, it is unclear what direction to take to counteract or promote certain bias data trends.
Works Cited:
Brandom, Russell. “Amazon Needs to Come Clean about Racial Bias in Its Algorithms.” The Verge, The Verge, 23 May 2018, www.theverge.com/2018/5/23/17384632/amazon-rekognition-facial-recognition-racial-bias-audit-data.
Charlescearl. “Gender and Racial Bias in Cloud NLP Sentiment APIs.” Data for Breakfast, 22 Aug. 2019, data.blog/2019/08/21/gender-and-racial-bias-in-cloud-nlp-sentiment-apis/.
Garbade, Michael J. “A Simple Introduction to Natural Language Processing.” Medium, Becoming Human: Artificial Intelligence Magazine, 15 Oct. 2018, becominghuman.ai/a-simple-introduction-to-natural-language-processing-ea66a1747b32.
Garimella, Aparna, et al. “Women’s Syntactic Resilience and Men’s Grammatical Luck: Gender-Bias in Part-of-Speech Tagging and Dependency Parsing.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, doi:10.18653/v1/p19-1339.
Liu, Xiaohua, et al. “QuickView.” Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information - SIGIR 11, 2011, doi:10.1145/2009916.2010157.
“Natural Language Computing.” Microsoft Research, www.microsoft.com/en-us/research/group/natural-language-computing/.
Noble, Safiya Umoja. Algorithms of Oppression: How Search Engines Reinforce Racism. New York University Press, 2018.
Olteanu, Alexandra, et al. “Social Data: Biases, Methodological Pitfalls, and Ethical Boundaries.” SSRN Electronic Journal, 2016, doi:10.2139/ssrn.2886526.
Ott, Myle, et al. “New Advances in Natural Language Processing to Better Connect People.” Facebook AI Blog, ai.facebook.com/blog/new-advances-in-natural-language-processing-to-better-connect-people/.
Sun, Tony, et al. “Mitigating Gender Bias in Natural Language Processing: Literature Review.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, doi:10.18653/v1/p19-1159.
The Social Impact of Natural Language Processing - Dirk Hovy. www.dirkhovy.com/portfolio/papers/download/ethics.pdf.
Author's Notes:
I apologize for formatting. As soon as I uploaded pictures the entire post has become glitchy, even to edits.
Comments
Post a Comment